BAB 9
Analisis Regresi dan analisis korelasi
Pengertian : Analisis regresi
merupakan salah satu analisis yang bertujuan untuk mengetahui pengaruh
suatu variabel terhadap variabel lain. Dalam analisis regresi, variabel
yang mempengaruhi disebut Independent Variable (variabel bebas) dan
variabel yang dipengaruhi disebut Dependent Variable (variabel terikat).
Jika dalam persamaan regresi hanya terdapat satu variabel bebas dan
satu variabel terikat, maka disebut sebagai persamaan regresi sederhana,
sedangkan jika variabel bebasnya lebih dari satu, maka disebut sebagai
persamaan regresi berganda.
Analisis Korelasi merupakan suatu analisis untuk mengetahui tingkat keeratan hubungan antara dua variabel. Tingkat hubungan tersebut dapat dibagi menjadi tiga kriteria, yaitu mempunyai hubungan positif, mempunyai hubungan negatif dan tidak mempunyai hubungan.
Analisis Regresi Sederhana : digunakan untuk mengetahui pengaruh dari variabel bebas terhadap variabel terikat atau dengan kata lain untuk mengetahui seberapa jauh perubahan variabel bebas dalam mempengaruhi variabel terikat. Dalam analisis regresi sederhana, pengaruh satu variabel bebas terhadap variabel terikat dapat dibuat persamaan sebagai berikut :
Y = a
+ b X
Keterangan :Y : Variabel terikat (Dependent Variable);
X :
Variabel bebas (Independent Variable);
a : Konstanta; dan
b : Koefisien
Regresi.
Untuk mencari persamaan garis regresi dapat digunakan berbagai
pendekatan (rumus), sehingga nilai konstanta (a) dan nilai koefisien
regresi (b) dapat dicari dengan metode sebagai berikut :
a = [(ΣY . ΣX2) – (ΣX . ΣXY)] / [(N . ΣX2) – (ΣX)2] atau a = (ΣY/N) – b (ΣX/N)
b = [N(ΣXY) – (ΣX . ΣY)] / [(N . ΣX2) – (ΣX)2]
Contoh :
Berdasarkan hasil pengambilan sampel secara acak tentang pengaruh lamanya belajar (X) terhadap nilai ujian (Y) adalah sebagai berikut :
a = [(ΣY . ΣX2) – (ΣX . ΣXY)] / [(N . ΣX2) – (ΣX)2] atau a = (ΣY/N) – b (ΣX/N)
b = [N(ΣXY) – (ΣX . ΣY)] / [(N . ΣX2) – (ΣX)2]
Contoh :
Berdasarkan hasil pengambilan sampel secara acak tentang pengaruh lamanya belajar (X) terhadap nilai ujian (Y) adalah sebagai berikut :
(nilai ujian)
|
X (lama belajar)
|
X 2
|
XY
|
40
|
4
|
16
|
160
|
60
|
6
|
36
|
360
|
50
|
7
|
49
|
350
|
70
|
10
|
100
|
700
|
90
|
13
|
169
|
1.170
|
ΣY = 310
|
ΣX = 40
|
ΣX2 = 370
|
ΣXY = 2.740
|
Dengan menggunakan rumus di atas, nilai a dan b akan diperoleh sebagai berikut :
a = [(ΣY . ΣX2) – (ΣX . ΣXY)] / [(N . ΣX2) – (ΣX)2]
a = [(310 . 370) – (40 . 2.740)] / [(5 . 370) – 402] = 20,4
b = [N(ΣXY) – (ΣX . ΣY)] / [(N . ΣX2) – (ΣX)2]
b = [(5 . 2.740) – (40 . 310] / [(5 . 370) – 402] = 5,4
Sehingga persamaan regresi sederhana adalah Y = 20,4 + 5,2 X
Berdasarkan hasil penghitungan dan persamaan regresi sederhana tersebut di atas, maka dapat diketahui bahwa :
a = [(ΣY . ΣX2) – (ΣX . ΣXY)] / [(N . ΣX2) – (ΣX)2]
a = [(310 . 370) – (40 . 2.740)] / [(5 . 370) – 402] = 20,4
b = [N(ΣXY) – (ΣX . ΣY)] / [(N . ΣX2) – (ΣX)2]
b = [(5 . 2.740) – (40 . 310] / [(5 . 370) – 402] = 5,4
Sehingga persamaan regresi sederhana adalah Y = 20,4 + 5,2 X
Berdasarkan hasil penghitungan dan persamaan regresi sederhana tersebut di atas, maka dapat diketahui bahwa :
1) Lamanya belajar mempunyai pengaruh
positif (koefisien regresi (b) = 5,2) terhadap nilai ujian, artinya jika
semakin lama dalam belajar maka akan semakin baik atau tinggi nilai
ujiannya;
2) Nilai konstanta adalah sebesar 20,4, artinya jika tidak
belajar atau lama belajar sama dengan nol, maka nilai ujian adalah
sebesar 20,4 dengan asumsi variabel-variabel lain yang dapat
mempengaruhi dianggap tetap.
Analisis Korelasi (r) : digunakan untuk
mengukur tinggi redahnya derajat hubungan antar variabel yang diteliti.
Tinggi rendahnya derajat keeratan tersebut dapat dilihat dari koefisien
korelasinya. Koefisien korelasi yang mendekati angka + 1 berarti terjadi
hubungan positif yang erat, bila mendekati angka – 1 berarti terjadi
hubungan negatif yang erat. Sedangkan koefisien korelasi mendekati angka
0 (nol) berarti hubungan kedua variabel adalah lemah atau tidak erat.
Dengan demikian nilai koefisien korelasi adalah – 1 ≤ r ≤ + 1. Untuk
koefisien korelasi sama dengan – 1 atau + 1 berarti hubungan kedua
variabel adalah sangat erat atau sangat sempurna dan hal ini sangat
jarang terjadi dalam data riil. Untuk mencari nilai koefisen korelasi
(r) dapat digunakan rumus sebagai berikut : r = [(N . ΣXY) – (ΣX . ΣY)] /
√{[(N . ΣX2) – (ΣX)2] . [(N . ΣY2) – (ΣY)2]}
Contoh :
Sampel yang diambil secara acak dari 5 mahasiswa, didapat data nilai Statistik dan Matematika sebagai berikut :
Contoh :
Sampel yang diambil secara acak dari 5 mahasiswa, didapat data nilai Statistik dan Matematika sebagai berikut :
Sampel
|
X (statistik)
|
Y (matematika)
|
XY
|
X2
|
Y2
|
1
|
2
|
3
|
6
|
4
|
9
|
2
|
5
|
4
|
20
|
25
|
16
|
3
|
3
|
4
|
12
|
9
|
16
|
4
|
7
|
8
|
56
|
49
|
64
|
5
|
8
|
9
|
72
|
64
|
81
|
Jumlah
|
25
|
28
|
166
|
151
|
186
|
r = [(5 . 166) – (25 . 28) / √{[(5 . 151) – (25)2] . [(5 . 186) – (28)2]} = 0,94
Nilai koefisien korelasi sebesar 0,94 atau 94 % menggambarkan bahwa antara nilai statistik dan matematika mempunyai hubungan positif dan hubungannya erat, yaitu jika mahasiswa mempunyai nilai statistiknya baik maka nilai matematikanya juga akan baik dan sebaliknya jika nilai statistik jelek maka nilai matematikanya juga jelek.

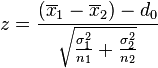


 tidak diketahui
tidak diketahui

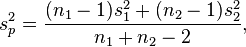
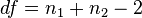



 digabungkan
digabungkan
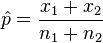
 tidak digabung
tidak digabung



 >
>  dan H0 ditolak jika
dan H0 ditolak jika 
 , probabilitas melakukan kesalahan tipe I (menolak hipotesis nol pada saat hipotesis nol benar)
, probabilitas melakukan kesalahan tipe I (menolak hipotesis nol pada saat hipotesis nol benar) = Jumlah sampel
= Jumlah sampel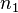 = Jumlah sampel 1
= Jumlah sampel 1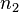 = Jumlah sampel 2
= Jumlah sampel 2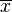 = Rata-rata sampel
= Rata-rata sampel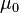 = Dugaan rata-rata populasi
= Dugaan rata-rata populasi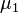 = Rata-rata populasi 1
= Rata-rata populasi 1 = Rata-rata populasi 2
= Rata-rata populasi 2 =
=  =
=  = Penjumlahan(dari angka sejumlak k)
= Penjumlahan(dari angka sejumlak k)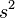 =
=  = Simpangan baku sampe 1
= Simpangan baku sampe 1 = Simpangan baku sampe 2
= Simpangan baku sampe 2 =
=  =
=  = Rata-rata perbedaan sampel
= Rata-rata perbedaan sampel = Dugaan rata-rata perbedaan populasi
= Dugaan rata-rata perbedaan populasi = Simpangan baku perbedaan
= Simpangan baku perbedaan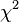 =
= 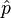 = x/n = Proporsi sampel, (kecuali ditentukan sebelumnya)
= x/n = Proporsi sampel, (kecuali ditentukan sebelumnya)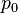 = Dugaan proporsi populasi
= Dugaan proporsi populasi = proporsi 1
= proporsi 1 = proporsi 2
= proporsi 2 = Dugaan perbedaan proporsi
= Dugaan perbedaan proporsi = minimum of n1 and n2
= minimum of n1 and n2

 =
=